Obsah
Zadání
16. Hlavní metody formální verifikace softwarových systémů
Vypracování
Vypracování této otázky je postaveno především na předmětu IA159 Formal Verification Methods s tím, že se odkazuje na model checking popsaný v otázce modální a temporální logiky a popsaný v předmětu IV113 Úvod do validace a verifikace. Většina věcí není popsaná moc do detailů, ale celkově by to měl být dobrý přehled.
Úvod
Verifikace řeší následující problém: Vytváříme něco (program, systém, protokol, …) podle zadání. Splňuje výsledný výtvor zadání? Formální je v tom smyslu, že pro tento účel používá metody založené na matematických teoriích (logika, automaty, teorie grafů, …). Cílem je pak prokázat, že systém pracuje správně takovým způsobem, aby míra důvěry ve výsledek verifikace byla stejná jako míra důvěry v matematický důkaz1) Tento problém se typicky redukuje na to, jestli daný systém (program) splňuje danou vlastnost – specifikaci (zadání). Samozřejmě, předpokladem je, aby byla specifikace zapsána formálně (zde je třeba zdůraznit důležitost specifikace obecně – můžeme něco vytvořit správně, pokud nemáme dobře formulované zadání?).
Tolik teorie. V praxi je použití metod formální verifikace trochu složitější. Ideální metoda by byla taková, která je automatická, lze aplikovat přímo na zdrojový kód a dokáže s jistotou určit jestli program splňuje specifikaci (specifikaci se asi nevyhneme). Přitom by měla být dostatečně efektivní.
Typické metody místo se zdrojovým kódem programu pracují s modelem programu (jeho abstraktní reprezentací). To s sebou přináší následující problémy:
- Je třeba model vytvořit. Existuje snaha na automatický převod zdrojového kódu na model, což v zásadě odpovídá aplikaci na zdrojový kód – pozor, stále se na něj může vztahovat třetí z problémů (viz níže).
- Je třeba ověřit, že model odpovídá zdrojovému kódu2).
- Jazyk specifikace modelu nemusí obsahovat všechny prvky reálného programu (typicky volání operačního systému a práce se zdroji, které jsou často zdrojem chyb).
Poměrně zásadním problémem formální verifikace je efektivita. Aby byly použitelné v praxi, musí často slevit z ostatních požadavků. Typicky umožňují jednostrannou chybu (více viz Abstrakce).
Dokazování korektnosti (deductive verification, theorem proving)
Dokazování korektnosti je nejstarší metodou formální verifikace. Slouží k ověření vstupně-výstupního chování algoritmu, pročež se vytvoří formální důkaz, že pro vstup splňující vstupní podmínku algoritmus skončí (terminace) a jeho výstup splňuje výstupní podmínku (parciální korektnost). Je jasné, že něco takového je možné pouze pro programy, které skončí a navíc je v zásadě nepoužitelná pro paralelní záležitosti. Dále, ačkoliv je možné v zásadě vytvořit důkaz na základě zdrojového kódu, důkaz často nebere v potaz některé záležitosti reálného světa (HW, …).
Hlavní nevýhoda dokazování korektnosti je však následující: tato metoda je velmi obtížně automatizovatelná (problém zastavení) a spoléhá na lidského operátora, který důkaz vytváří. Počítačové nástroje dokáží člověku usnadnit práci (především ověřit, že někde neudělal chybu). Navíc vytvářet důkazy nemůže kdokoli: operátor musí být dobrý matematik (důkazy), programátor a zároveň detailně znát doménu programu, tj. to, co program počítá.
Z těchto důvodů se dokazování používá pouze pro kritické systémy.
Přístupy
Jak přesně je důkaz vystavěn, záleží na tom, jaké programovací paradigma je použito. Pokud je program napsán v deklarativním programovacím jazyce (především funkcionálním), používají se přímo matematické důkazy a indukce (pro rekurzívních funkcí). Samozřejmě to vyžaduje, aby jazyk byl referenčně transparentní.
U imperativních programů se typicky pracuje s invarianty. Každému místu v programu – mezi dvěma příkazy – se přiřadí logická formule, kterou program, když prochází tímto místem, musí splňovat. Přitom na začátku programu je vstupní a na jeho konci výstupní podmínka. Pak se pro každý příkaz dokáže, že pokud platí podmínka před ním a příkaz se provede, bude platit podmínka po něm. Lze na to nahlížet tak, že se program rozbije na minimální imperativní programy, pro každý se určí vstupní a výstupní podmínka tak, aby na sebe navazovaly a dokáže se korektnost těchto podprogramů. Více viz axiomatická sémantika a Hoareho logika.
Druhá podmínka korektnosti pro imperativní programy je ukončení. Zde jsou problémem hlavně cykly. Proto se přiřadí ke každému cyklu nějaká funkce na proměnných, dokáže se, že je zdola omezená (například podmínkou ukončující cyklus) a že s každým průchodem cyklem klesá.
Theorem provery
Theorem prover (nebo také proof assistant) je nástroj, který má částečně automatizovat a usnadnit proces vytváření důkazu. Výhoda jejich použití je, že zvládnou některé jednoduché, ale časově náročné a únavné úkoly a zaručí, zmenší pravděpodobnost chyby. Většina těchto nástrojů je založena na funkcionálních jazycích.
Práce s theoremy provery je založena na dialogu mezi nástrojem a uživatelem (operátorem). Operátor zadává definice a věty, které chce dokázat, a nástroj ověřuje jejich korektnost, popřípadě se snaží je dokázat za pomocí přepisovacích pravidel, která jsou dána už dokázanými věcmi (existují celé knihovny často používaných vět). Může mít i heuristiku pro navržení schématu pro důkaz indukcí. V okamžiku, kdy si theorem prover neví rady (což je často), obrátí se na uživatele, aby zadal nějaké další pomocné tvrzení.
Celkově lze na tento proces pohlížet tak, že operátor vede theorem prover při vytváření důkazu.
Velmi známý theorem prover je ACL2 založený na Lispu. Více viz například http://en.wikipedia.org/wiki/Proof_assistant.
Model checking (ověřování modelu)
Model checking je automatická procedura, která rozhoduje, zda model systému splňuje danou vlastnost. Obojí musí být samozřejmě formálně zadáno.
Model systému jeho stavový prostor, který je zapsán ve formě přechodového systému (stavy a přechody mezi nimi). Pro program jsou stavy typicky dány ohodnocením všech proměnných a každému příkazu odpovídá přechod (nebo více přechodů), což je v zásadě small-step operační sémantika (viz 12-tei). Nic nám ale nebrání definovat stavový prostor jinak, typicky více abstraktně. Model/stavový prostor může být definovaný explicitně, tedy jako množina stavů a přechodová relace, nebo implicitně, tedy pomocí počátečního stavu a funkce, která pro libovolný stav vrací následníky. Toho se využije obzvlášť v případě, že je stavový prostor velký.
Vlastnosti se formálně zapisují jako formule vhodné logiky. Model checking je úzce svázaný s temporálními logikami, které popisují chování systému:
- Lineární temporální logika (linear temporal logic – LTL) se vyjadřuje o nekonečných bězích ve stavovém prostoru.
- Logika výpočtového stromu (computational tree logic – CTL) se vyjadřuje o stromové struktuře vyjadřující jak může výpočet z daného stavu pokračovat.
Tyto temporální logiky jsou do detailů popsány v samostatném článku, kde je rovněž rámcově popsáno, jak probíhá model checking. Výsledkem této procedury je buď tvrzení, že model splňuje vlastnost, nebo tvrzení že ji nesplňuje a (v ideálním případě) protipříklad, tedy příklad chování systému, které ji porušuje.
V průběhu model checkingu dochází v určitém smyslu k průzkumu stavového prostoru. Z toho vyplývá jeho zásadní omezení: stavový prostor musí být konečný3).
Dalším omezením je, co jde vyjádřit pomocí temporálních logik. Především, temporální logiky se vyjadřují o konkrétním chováním, nemůžeme použít proměnné. Není tedy možné ověřit, že procedura fact spočítá faktoriál (tedy že fact(n)=n!). Je ale možné vyjádřit, že fact(5)=120. To jim ale nebrání vyjádřit celou řadu zajímavých vlastností, jako například:
- safety (nedostanu se do chybného stavu),
- liveness (vždycky po nějaké – předem nespecifikované době – nastane dobrý stav),
- response (jeden stav je vždy – po nějaké době – následován jiným), …
To co není specifikováno jako vlastnost, se samozřejmě nekonotroluje, proto je nutné klást důraz na dobře provedenou specifikaci.
Co se týče praktického užití, má model checking následující problémy:
- Je třeba vytvořit model systému. Pokud je jazyk pro specifikaci modelu jiný než jazyk pro napsání programu, je to práce navíc (i když existuje snaha o automatizaci tohoto kroku). Proto se nejvíce model checking zatím uplatňuje v návrhu HW, který lze podle modelovacího jazyka přímo vyrábět.
- Aby člověk mohl vytvářet specifikaci (vlastnosti, které má model splňovat), musí dobře ovládat temporální logiky, což činí problémy i některým informatikům. Tento problém se nejčastěji (alespoň částečně) řeší pomocí „paterns“, což jsou věty v přirozeném jazyce, do kterých se doplňují jednoduché vlastnosti a jdou přímo přeložit do temporální logiky. Příklad takové věty (response pattern) je: „pokud nastane … pak vždy po nějaké době nastane …“.
- Stavové prostory reálných systémů jsou obrovské. Ačkoliv model checking je efektivní v tom smyslu, že jeho časová (a prostorová) složitost jsou lineární vůči stavovému prostoru, narážíme v praxi jak na to, že nejsme schopni model checking v rozumném čase upočítat, tak na to, že nám nestačí paměť.
Třetí problém je pravděpodobně nejzávažnější a v praxi se mu věnuje největší pozornost. Na FI probíhá dlouhodobý výzkum paralelizace a distribuce model checkingu.
Abstrakce
Jedna z možností redukce stavového prostoru (a to nejen pro model checking, ale pro něj je tento problém nejpalčivější), je abstrakce, tedy nahrazení konkrétních stavů (ohodnocení stavů) abstraktnějšími stavy, kterých je méně. Samozřejmě, tím se může chování systému (ať už vyjádřené jako množina možných běhů nebo množina možných výpočetních stromů) měnit. Rozeznáváme tři užitečné druhy abstrakce4):
- přesná abstrakce (exact abstraction) – abstraktní a konkrétní model mají stejné chování.
- overaproximace (nadaproximace?) – abstraktní model vykazuje všechno chování, co konkrétní a ještě něco navíc.
- underapproximace (podaproximace?) – abstraktní model vykazuje podmnožinu chování konkrétního.
Vztah výsledku model checkingu na abstraktním systému a splnění vlastnosti konkrétním systémem:
| přesná abstrakce | overaproximace | underapproximace | ||||
|---|---|---|---|---|---|---|
| abstraktní model vlastnost | splňuje | nesplňuje | splňuje | nesplňuje | splňuje | nesplňuje |
| konkrétní model vlastnost | splňuje | nesplňuje | splňuje | ? | ? | nesplňuje |
Pokud overaproximativní abstraktní model vlastnost nesplňuje, mohlo se to stát díky chování, které konkrétní model neobsahuje. Je tedy třeba ověřit, jestli vrácený protipříklad není falešný. Podobně, pokud underaproximativní abstraktní model vlastnost splňuje, nemusí to nic znamenat, protože jsme neprozkoumali všechno chování. Underapproximace tedy z model checkingu dělá „bug finding“5).
Výběr vhodné abstrakce není jednoduchý a typicky se váže ke zkoumané vlatsnosti (formuli).
Přesné abstrakce
Přesné abstrakce jsou užitečné a v praxi používané, na druhou stranu často nevedou k velkému snížení stavového prostoru. Typickým (a nejpoužívanějším) příkladem je zbavit se proměnných, které neovlivní splňenost formule (v angličtině se tomu říká „cone of influence“). To znamená vzít na začátku proměnné, které se přímo vyskytují v atomických propozicích zkoumané formule a postupně přidávat proměnné, ze kterých se počítají a proměnné, které řídí větvení programu (tranzitivně).
Nepřesné abstrakce
Existují dva způsoby jak provést nepřesnou abstrakci – ať už overaproximaci nebo underaproximaci:
- Doménová abstrakce – pro každou proměnnou určím abstraktní doménu hodnot. Typicky se používá (pro celočíselné proměnné) abstrakce na -1 (záporná čísla), 0, 1 (kladná čísla), abstrakce modulo n, abstrakce na sudá a lichá čísla a podobné.
- Predikátová abstrakce – určím si sadu predikátů na proměnných (x>n a podobně) a výsledný stav je dán pravdivostní hodnotou hodnotou těchto predikátů6). Je vidět, že predikátová abstrakce je obecnější.
Tím dostanu sadu abstraktních stavů. Over- a underaproximace se liší tím, které z přechodů vezmu. Mějme dva abstraktní stavy, s a t, které jsou spojením množin konkrétních stavů S a T. V abstraktním modelu je přechod z s do to:
- když je přechod z některého stavu v S do některého stavu z T (tzv. may-abstrakce – overaproximace),
- když z každého stavu v S vede přechod do některého stavu z T (tzv. must-abstrakce – underaproximace).
CEGAR
Counter-example guided abstraction refinement (vylepšování abstrakce řízené protipříklady) je nejmodernější technika využívající model checking. Funguje následovně:
- Udělám nějakou jednoduchou predikátovou overaproximaci na modelu (typicky založenou na atomických propozicích zkoumané formule).
- Provedu model checking. Pokud vyjde pozitivní výsledek, končím.
- Pokud dostanu protipříklad, zkontroluju, jestli je falešný. Pokud není, končím.
- Pokud je protipříklad falešný, přidám do abstrakce další predikát, který zaručí, že protipříklad nemůže nastat a pokračuju krokem 2.
Rozhodnout, zda je protipříklad falešný a vybrat predikát, který jej odstraní z množiny chování, není jednoduché.
Tato procedura nemusí vždy skončit, v praxi ale většinou skončí rychle.
Symbolická exekuce
Testování funguje tak, že necháme proběhnout program s jedním konkrétním vstupem. Problémem samozřejmě je, že zjistíme, jak se program chová, pouze pro tento jeden konkrétní vstup. Symbolická exekuce se snaží spustit program pro všechny možné vstupy najednou. Dělá to tak, že místo konkrétního vstupu pracuje se symbolem a proměnné obsahují výrazy nad symboly (například pokud v proměnné x je výraz a a v proměnné y výraz b+c, po přiřazení x := x * y je v proměnné x výraz a(b+c)). Samozřejmě, problém může být, když se do hry dostanou podmínky a cykly.
Mějme jednoduchý programovací jazyk s celočíselnými proměnnými a výrazy, které obsahují pouze sčítání, odčítání a násobení. Používáme příkazy:
- přiřazení, kdy do proměnné se přiřadí výraz,
- podmíněné větvení IF s podmínkou typu
, kde
je výraz,
- skoky (které jsou zde jako náhrada cyklů – skočí před podmínku).
Při symbolické exekuci programu na začátku do každé vstupní proměnné přiřadíme symbol
. To je taky jediná možnost zavedení symbolů. Proměnné pak obsahují polynomy nad těmito symboly. Navíc si zavedeme proměnnou
, tak zvanou podmínku cesty (path condition), která je konjunkcí výrazů typu
a
, kde
je polynom nad symboly
, což je v zásadě podmínka, kterou získáme, když dosadíme do podmínky příkazu IF hodnoty proměnných, a její negace. Na začátku je prázdná (i.e. pravdivá).
Pokud narazíme na příkaz přiřazení, vyhodnotíme výraz na pravé straně, čímž získáme polynom nad symboly, který uložíme do proměnné. Sémantika skoků zůstává nezměněna. V okamžiku, kdy narazíme na IF s podmínkou , jsou tři možné případy (předpokládáme, že následující implikace jsme schopni automaticky vyhodnotit):
– pokračujeme větví pro
true,– pokračujeme větví pro
false,- ani jedno z toho neplatí – musíme pokračovat oběma větvemi. Duplikujeme tedy stav (ohodnocení proměnných). Pro jeden z nich vezmeme
a pokračujeme větví pro
true, pro druhýa pokračujeme větví pro
false. Vzniká nám tak zvaný strom symbolického výpočtu (v zásadě se to velmi podobá struktuře, se kterou pracuje CTL), který je dán rozdvojováním symbolického výpočtu na příkazech IF.
Z toho je vidět, že v každém kroku výpočtu vyjadřuje co musí vstupní proměnné splňovat, abychom se do něj dostali.
Symbolická exekuce má jednu pěknou vlasnost. Do každého jeho uzlu se můžu dostat pro nějakou konkrétní (tedy ne symbolickou) hodnotu proměnných. To je způsobeno tím, že vždy , tedy existuje nějaké ohodnocení proměnných, které ji splňuje, a které tedy vede do daného stavu.
Jak použít symbolickou exekuci pro verifikaci? Obohatíme zdrojový kód o dvojici příkazů:
ASSUME(), který vyjadřuje vstupní podmínku a provede
,
ASSERT(.
Tak jak je výše popsána, vypadá symbolická exekuce jako velmi dobrá metoda. Má ale své problémy. Zaprvé, obecně nelze automaticky vyhodnotit , což potřebujeme při vyhodnocení příkazů IF a ASSERT. Druhým problémem jsou cykly. Pokaždé, když symbolická exekuce projde tělem cyklu, musí vyhodnotit podmínku, a tedy s velkou pravděpodobností dojde k větvení. To vede k explozi počtu větví výpočtu.
Třetím zásadním problémem je, že ne vše, co se s hodnotami proměnných v reálných programech děje, lze dobře provést se symbolickými hodnotami. Obzvlášť problematické je interpretovat:
- pole, pokud použijeme jako index symbolickou hodnotu,
- složité matematické operace typu hashování,
- ukazatele (adresy v paměti),
- volání operačního systému a knihoven.
Tyto problémy se typicky řeší pomocí „concolic execution“ (concrete + symbolic), kdy na začátku dostaneme konkrétní hodnoty vstupů a zároveň program vyhodnocujeme s konkrétními (jako u testování) a symbolickými hodnotami s tím, že pokud se dostaneme k příkazu IF, symbolická exekuce se nevětví, ale je použita ta větev, která odpovídá konkrétním hodnotám (a odpovídajícím způsobem se upraví podmínka cesty) a pokud není dostupná symbolická hodnota (např. u adres nebo hashování), použije se konkrétni. Na tento způsob použití už ale nemůžeme pohlížet jako na verifikaci. V zásadě je to testování s dodatečnou informací ve formě podmínky cesty.
V praxi se tedy symbolická exekuce používá jako doplňek testování. Pozor, oproti testování je provedení symbolické exekuce výpočtově náročnější (kvůli symbolickým operacím s polynomy).
Automated whitebox fuzz testing
Automated whitebox fuzz testing je technika, která využívá k vytváření testů toho, jak vypadá zdrojový kód programu (whitebox) a vstupy generuje náhodně (fuzz). Probíhá tak, že se náhodně vybere vstup a provede se „concolic execution“ na programu. Pokud je test úspěšný, vstup se náhodně změní tak, aby nevyhovovaly vypočítané . Tím by se mělo dosáhnout pokrytí více různých průchodů programem za použití méně testů. Samozřejmě, problém je, že symbolická exekuce je drahá, a je tedy třeba dobře vybírat, která upravená hodnota vstupu se použije.
Statická analýza a abstraktní interpretace
Vezměme si nějaký imperativní program reprezentovaný jeho grafem toku řízení (uzly jsou jednotlivé příkazy a orientované hrany spojují ty příkazy, které za sebou mohou následovat). V každém místě (která odpovídají hranám) se program může nacházet ve více stavech (například při provádění cyklu projde jedním místem několikrát). Abstraktní interpretace vytváří statickou sémantiku která aproximuje tyto množiny stavů. Stavy můžou být jednak konkrétní (ohodnocení proměnných), ale i abstraktní (například proměnné, které mají definovanou hodnotu, …).
Statická analýza je starší pojem a zahrnuje různé úlohy, které se provádí nad grafem toku řízení a typicky se používají v překladačích (klasickým případem je hledání nedostupného – mrtvého – kódu). Všechny úlohy statické analýzy se dají vyjádřit v rámci abstraktní interpretace.
Jak to funguje? Předcházející vysvětlení zní dost abstraktně (abstraktní interpretace …), takže si to uvedeme na příkladu živých proměnných ze statické analýzy. Proměnná je živá, pokud její současnou hodnotu můžeme někdy v budoucnu potřebovat. Hodnoty živých proměnných je tedy třeba uchovat. Oproti tomu, pokud dvě proměnné nejsou nikdy zároveň živé, můžeme jejich hodnoty ukládat do jednoho registru. Platí přitom pozorování:
- Pokud přiřazujeme do proměnné, není před tímto přiřazením živá.
- Pokud je v příkazu proměnná součástí výrazu, je před tímto příkazem živá.
- Jinak se živé proměnné přes příkaz zachovávají.
Obecný postup při abstraktní interpretaci je následující:
- Určíme si množinu abstraktních stavů – proměnné. Výsledkem analýzy bude pro každé místo v toku řízení množina stavů – pro každé místo lze určit množina živých proměnných.
- Určíme statickou sémantiku – pro každé místo (efektivní) funkci, která počítá množinu stavů pro dané místo na základě stavů v jiných místech – podíváme se na příkaz následující po místě a množinu míst přímo následujících po tomto stavu (v tomto pořadí):
- Pokud je proměnná živá v jednom z následujících míst, je živá v tomto místě (zřejmě na konci není žádná proměnná živá).
- Pokud příkaz přiřazuje do proměnné, odebereme ji ze živých proměnných.
- Pokud příkaz používá hodnotu proměnné ve výrazu, přidáme ji do živých proměnných.
- Tuto soustavu rekurzívních rovnic vyřešíme/vypočítáme, čímž dostaneme výsledek. Na začátku každému svazu přiřadíme prázdnou množinu a pak postupně aplikujeme funkce, dokud nedojdeme k pevnému bodu (to funguje díky Kleeneho větě o pevném bodě – viz níže).
To že má soustava rovnic řešení spoléhá dvě matematické věty: Knasterovu-Tarského větu, která říká, že pevné body monotónní funkce na úplném svazu tvoří úplný svaz, a Kleeneho větu o pevném bodě, která říká, že nejmenší pevný bod monotónní funkce na úplném svazu lze spočítat její postupnou iterací na nejmenším prvku – za předpokladu, že svaz má konečnou výšku (tj. neobsahuje nekonečný stoupající řetěz). Z toho důvodu musí platit, že množina stavů musí tvořit úplný svaz s konečnou výškou (například podmnožiny libovolné konečné množiny s relací podmnožiny) a relace a funkce pro jednotlivé stavy musí být monotónní (vzhledem k relaci uspořádání pro daný úplný svaz). Existují však i metody pro aproximaci výpočtu pokud svaz nemá konečnou výšku (například přirozená čísla)7).
Poznámka: Výše byla abstraktní interpretace definována na množinách stavů, což je nejpřirozenější úplný svaz (podmnožiny množiny). Lze použít i jiný úplný svaz a každému svazu přiřazovat něco jiného než množinu stavů.
Abstraktní interpretace formálně
Nechť 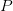 je program s
je program s 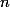 místy. Jeho abstraktní interpretace je šestice
místy. Jeho abstraktní interpretace je šestice 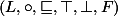 , kde
, kde 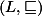 tvoří úplný svaz s nejnižším prvkem
tvoří úplný svaz s nejnižším prvkem 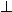 a nejvyšším
a nejvyšším 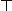 a
a  je buď jeho operace spojení nebo průseku (suprema nebo infima pro dva prvky). Funkce
je buď jeho operace spojení nebo průseku (suprema nebo infima pro dva prvky). Funkce 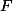 je pak monotónní funkce na svazu
je pak monotónní funkce na svazu 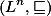 , kde
, kde 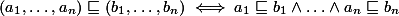 (technická záležitost – funkce pro všechna místa najednou) Platí přitom, že pokud je úplný svaz, je taky úplný svaz.
(technická záležitost – funkce pro všechna místa najednou) Platí přitom, že pokud je úplný svaz, je taky úplný svaz.
V praxi je abstraktní interpretace dobrá metoda, protože lze aplikovat přímo na zdrojový kód. Je široce používaná především v překladačích. Co se týče věcí, které s její pomocí lze ověřit (a chyby, které lze najít), řeší většinou úplně trochu jiné věci než ostatní metody.
Problémy bitového vektoru
Tyto problémy jsou součástí statické analýzy, jedním z nichž je problém živých proměnných. Jejich název je odvozen od toho, že používají konečné množiny stavů, které se dají reprezentovat jako vektor bitů. Jsou to lokální problémy v tom smyslu, že množina stavů pro místo se vypočítá jen ze stavů následujících (živé proměnné) nebo předcházejících míst – a to pomocí průniku nebo sjednocení (živé proměnné). Pokud se počítá z následujících stavů, také říkáme, že program procházíme zpětně, pokud z předházejících, dopředně.
| průnik | sjednocení | |
|---|---|---|
| předchozí místa | dostupné výrazy | dosažitelné definice |
| následující místa | využitelné výrazy | živé proměnné |
- Dosažitelné definice – definice proměnné je výraz na pravé straně přiřazení (tj. 'a+b' v 'x := a+b'). Definice (výraz) je v místě dostupná, pokud může být zdrojem současné hodnoty (tj. existuje cesta od přiřazení po současné místo, kde nebylo do proměnné přiřazováno).
- Dostupné výrazy – výraz je v daném místě živý, pokud byl nutně někdy v minulosti vyhodnocen a jeho hodnota (tj. ohodnocení použitých proměnných) se od té doby nezměnilo.
- Využitelné výrazy – výraz je v daném místě využitelný, pokud je někdy v budoucnu nutně použit a do té doby se nezmění jeho hodnota.
Testování
Testování není metoda formální verifikace per se. Na druhou stranu, v praxi se používá k podobným účelům jako níže uvedené metody, a proto je vhodné jej zmínit8).
Testování programu spočívá v jeho spuštění na jednom konkrétním vstupu a ověření, že výstup je správný (a nedošlo k chybě). Tato procedura se přitom typicky opakuje pro nějakou množinu vstupů. Samozřejmě každý test vypovídá pouze o chování programu na daném vstupu a až na výjimečné případy není možné otestovat všechny možné vstupy. Z toho důvodu sice testování dokáže odhalit chyby, ale pokud žádnou neodhalí, nemusí to znamenat, že program je správný. Proto není verifikační metodou, ale metodou na hledání chyb (bug finding) – někteří používají pojem „falsifikační metoda“. Základní výhodou testování je především to, že lze aplikovat přímo na zdrojový kód a v principu je to velmi jednoduchá metoda, která nevyžaduje hluboké teoretické znalosti.
Je třeba ale nutné říct, že některé z níže uvedených metod, pokud mají být použitelné v praxi, nemusí poskytnout definitivní odpověď o správnosti programu (viz symbolicka_exekuce, nebo underaproximace). Každopádně, testování rozhodně není formální metoda.
Existuje celá řada technik vytvořených za účelem efektivního testování. Více o nich viz materiály k předmětu IV113 Úvod do validace a verifikace.
Testování se podobá simulace, která se ale místo na reálném systému provádí na modelu. Ta se typicky používá při návrhu HW, který se nejprve navrhne v nějakém modelovacím jazyce, nad ním se provede simulace a pak se přímo z něj tisknou spoje.
Další metody
Tímto výčet formálních metod použitelných ve verifikaci nekončí. Zde jsou stručně zmíněny některé další.
Ověřování ekvivalence (equivalence checking)
Tato metoda zjišťuje, jestli jsou modely dvou systémů jsou v dané relaci ekvivalence. Typicky se používá bisimulační ekvivalence9). Tento proces je většinou omezen na konečné systémy, respektive, neexistují algoritmy pro použitelné ekvivalence na nekonečných systémech.
V praxi se používá v některých specifických oblastech (například ověřování, že si vzájemně odpovídají různé úrovně designu HW).
Satisfiabiliy Modulo Theories
Satisfiability Modulo Theories je problém splnitelnosti formule prvořádové logiky s rovností vzhledem k určitým teoriím. Typicky se používají:
- teorie aritmetiky celých čísel a reálných čísel,
- teorie datových struktur (axiomy popisující chování polí, …)
Problém (program a jeho vlasntost) se vyjádří jako taková formule. K té se vytvoří negace a k ní se testuje splnitelnost. Pokud není splnitelná, původní formule je platná, pokud je splnitelná, dostáváme konkrétní ohodnocení logických proměnných a tedy protipříklad.
Jedna z možností algoritmického řešení tohoto problému jsou SAT solvery – problém se převede na výrokové formule, které se vyřeší pomocí SAT solveru10). Jsou ale i jiné přístupy.
Předměty
- IV113 Úvod do validace a verifikace – zabývá se především model checkingem (a testováním), ostatní metody spíše ve stručnosti zmiňuje.
- IA159 Formal Verification Methods – dobrý popis ostatních metod, jde hodně do hloubky.
- PA008 Překladače – dotýká se spíše okrajově, konkrétně se v něm probírá statická analýza (a proč se provádí).
1)
Citovány slidy k předmětu IV113 Úvod do validace a verifikace.
2)
Poté co byla u některých procesorů Intel objevena chyba v práci s desetinnými čísly, se AMD chlubilo tím, že mají dokázáno, že jejich procesory počítají správně. Do jisté míry to byla pravda. Bylo formálně dokázáno, že model FPU (jetnotka pro práci s čísly s plovoucí desetinnou čárkou) použité v procesorech AMD počítá podle standardu IEEE pro aritmetiku čísel s plovoucí desetinnou čárkou. Avšak na ověření, že tento model odpovídá fyzické FPU, bylo použito testování (asi 80 000 000 testovacích výpočtů).
3)
Teoreticky lze provádět model checking na některých systémech s nekonečným stavovým prostorem – například existuje procedura pro model checking na zásobníkových automatech (PDA) – ale musí se nějakým způsobem omezit vyjadřovací možnosti. Například při formulování vlastností na PDA se nemůžu dívat hlouběji než na vrchol zásobníku. Více viz kurz IA159 Formal Verification Methods.
4)
Formálně je abstrakce definována v materiálech ke kurzu IA159 Formal Verification Methods.
5)
V praxi ji ale programátoři mají radši, protože vrácených falešných protipříkladů bývá mnoho a zjistit, jestli je protipříklad falešný, je náročná práce.
6)
V praxi se nejčastěji používají pravdivostní hodnoty ano/ne/nevím.
7)
Jsou to funkce rozšíření a zúžení. Více o nich je v materiálech k předmětu IA159 Formal Verification Methods.
8)
Ale začínat testováním pokud se dostanete tuto otázku u zkoušky není dobrý nápad.
9)
 Nejspíše by měla být na odkazované stránce, pokud nebude, měla by se hodit sem.
Nejspíše by měla být na odkazované stránce, pokud nebude, měla by se hodit sem.
Nejspíše by měla být na odkazované stránce, pokud nebude, měla by se hodit sem.