Toto je starší verze dokumentu!
—-
Obsah
IN-POS 1. Architektury operačních systémů
Zadání
- Struktury OS, služby OS, architektury OS,
- procesy a vlákna, plánování běhu procesů a vláken, komunikace a synchronizace procesů, uváznutí,
- správa paměti a virtualizace paměti,
- ovládání vstupů a výstupů.
- PB152, PA150
Vypracování
Struktury OS
Generické funkční komponenty OS:
- Správa procesorů
- Správa procesů a vláken
- Správa (hlavní, operační) paměti
- Správa souborů
- Správa I/O systémů
- Správa vnější (sekundární) paměti
- Networking (síťování)
- Systém ochran
- Interpret příkazů
- Systémové programy
Služby OS
- Provádění programů
- Přístup k IO zařízením
- Přístup k souborům dat
- Přístup k systémovým zdrojům
- Chybové řízení
- Protokolování
- Vývoj programů,…
Architektury OS
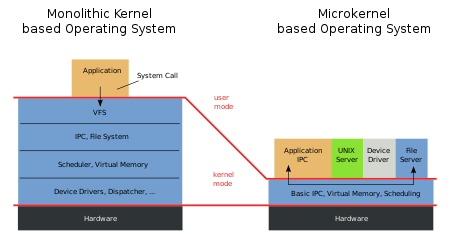
Mikrokernel / Mikrojádro
- Minimalistické jádro poskytující pouze základní funkcionalitu:
- správa přerušení,
- správa paměti,
- správa procesorů,
- správa procesů (komunikace mezi procesy pomocí zpráv).
- Zbytek funkcionality je mimo jádro (např. drivery, služby systému souboru, virtualizace paměti).
- příklad: MACH
- ➕ snadná přenositelnost OS, jádro je malé
- ➕ vyšší spolehlivost (moduly mají jasné API a jsou snadněji
testovatelné)
- ➕ vyšší bezpečnost (méně kódu OS běží v režimu jádra)
- ➕ flexibilita (jednodušší modifikace, přidání, odebrání modulů)
- ➕ všechny služby jsou poskytovány jednotně (výměnou zpráv)
- ➖ zvýšená režie (volání služeb je nahrazeno výměnou zpráv mezi procesy)
Makrokernel / Monolitické jádro
- Rozsáhlé jádro obsahující velké množství funkcionality v rámci jádra.
- Funkcionality pro většinu aspektů činností OS (např. správa souborových systémů)
- ➕ efektivnější komunikace (přímý přístup k celému jádru)
- ➖ náročnější údržba a verifikace velkého množství kódu
Modulární jádro
- Kompromis předchozích typů.
- Jde o modularitu kódu jádra ne o modulární architekturu jádra (mikrojádro).
- Značná část tvořena moduly, které lze přidávat a odebírat za běhu systému.
- Moduly běží stejně jako zbytek jádra v privilegovaném režimu (fakticky se jedná o monolitické jádro).
- příklad: Linux (LKM – Loadable Kernel Module)
- ➕ přidání funkcionality za běhu (např. nové USB zařízení)
- ➕ snížení paměťových nároků jádra (nahráváme jen moduly, které potřebujeme)
- ➖ vyšší režie oproti speciálně zkompilovanému jádru
- příklad: Windows
- Do jádra Windows můžeme za běhu vkládat ovladače bežící v privilegovaném režimu.
Procesy a vlákna
Proces
- Program zavedený do operační paměti, který je prováděn procesorem.
- Je jednoznačně rozpoznatelný (unikátní PID - Process ID).
- Hierarchie procesů – rodič-potomek, sourozenci
Význam procesu v OS
- OS maximalizuje využití procesoru prokládáním běhu procesů (minimalizuje tak dobu odpovědi).
- OS spravuje zdroje přidělováním procesům podle zvolené politiky (priorita, vzájemná výlučnost, zabraňuje uváznutí).
- OS podporuje tvorbu procesu a jejich komunikaci.
- OS s multiprogramováním multiprogramování = multitasking
Stavy procesu
- Nový - proces je právě vytvářen
- Běžící - proces je právě vykonáván nějakým CPU v systému
- Čekající - proces čeká na nějakou událost/události (například dokončení výpočtu jiného procesu)
- Připravený - proces čeká na přidělení procesoru, je připraven vykonávat svou úlohu
- Ukončený - proces ukončil svou činnost, ale ještě stále existuje

Informace OS o procesu
Process Control Block – tabulka obsahující informace potřebné pro definici a správu procesu
- stav procesu (běžící, připravený, …)
- čítač instrukcí
- registry procesoru
- informace potřebné pro správu paměti
- informace potřebné pro správu I/O
- účtovací informace
Vlákno
Objekt, který vzniká v rámci procesu, je viditelný pouze uvnitř procesu a je charakterizován svým stavem (CPU se přidělují vláknům).
Každé vlákno si udržuje svůj vlastní
- zásobník
- PC (program counter)
- registry
- TCB (Thread Context Block)
Vlákno může přistupovat k paměti a ostatním zdrojům svého procesu
- Zdroje procesu jsou sdíleny všemi vlákny jednoho procesu (př. otevřené soubory, úpravy buňky mimo zásobník).
Tři klíčové stavy vláken:
- běží
- připravený
- čekající
Vlákna se (samostatně) neodkládají.
- Všechna vlákna jednoho procesu sdílejí stejný adresový prostor.
Ukončení procesu ukončuje všechna vlákna existující v rámci procesu
Výhody:
- ➕ Vlákno se vytvoří rychleji než proces.
- ➕ Vlákno se ukončí rychleji než proces.
- ➕ Mezi vlákny se rychleji přepíná než mezi procesy.
- ➕ Jednodušší programování (jednodušší struktura programu).
- ➕ U multiprocesorových systémů může na různých procesorech běžet více vláken jednoho procesu současně.
- ➕ Když vlákno čeká na ukončení I/O operace, může běžet jiné vlákno téhož procesu, aniž by se přepínalo mezi procesy (což je časově náročné)
- ➕ Vlákna jednoho procesu sdílí paměť a deskriptory otevřených souborů a mohou mezi sebou komunikovat, aniž by k tomu potřebovaly služby jádra (což by bylo pomalejší)
Konzistence
Vlákna jedné aplikace se proto musí mezi sebou synchronizovat, aby se zachovala konzistentnost dat (musíme zabránit současné modifikaci stejných dat dvěma vlákny apod.)
Mapování
- 1:1
- UNIX Systém V, (MS-DOS)
- Pojem vlákno neznámý, každé „vlákno“ je procesem s vlastním adresovým prostorem a s vlastními prostředky.
- 1:M
- OS/2, Windows XP, Mach, …
- V rámci 1 procesu lze vytvořit více vláken.
- Proces je vlastníkem zdrojů (vlákna sdílejí zdroje procesu).
Podpora
User-Level Threads (ULT)
- Správa vláken se provádí prostřednictvím vláknové knihovny („thread library“) na úrovni uživatelského/aplikačního programu.
- ➕ Plánování je specifické pro konkrétní aplikaci.
- Aplikace volí si pro sebe nejvhodnější algoritmus.
- „Threads library“ obsahuje funkce pro:
- vytváření a rušení vláken předávání zpráv a dat mezi vlákny
- plánování běhů vláken
- uchovávání a obnova kontextů vláken
- Co dělá jádro pro vlákna na uživatelské úrovni:
- Jádro neví o aktivitě vláken, proto manipuluje s celými procesy.
- ➕ ULT mohou běžet pod kterýmkoliv OS
- není vyžadována podpora na úrovní jádra OS
- ➕ Přepojování mezi vlákny nepožaduje provádění jádra (tj.vyšší rychlost)
- Nepřepíná se ani kontext ani režim procesoru.
- ➖ Jádro může přidělovat procesor pouze procesům, dvě vlákna stejného procesu nemohou běžet na dvou procesorech.
- ➖ Většina volání služeb OS způsobí blokování celého procesu.
- Když některé vlákno zavolá službu jádra, je blokován celý proces dokud se služba nesplní (pro „thread library“ je takové vlákno ale stále ve stavu „běží“). Stavy vláken jsou na stavech procesu nezávislé.
Kernel-Level Threads (KLT)
- Správu vláken podporuje jádro, nepoužívá se „thread library“.
- Používá se API pro vláknové služby jádra.
- Informaci o kontextu procesů a vláken udržuje jádro.
- ➕ Jádro může současně plánovat běh více vláken stejného procesu na více procesorech.
- ➕ K blokování dochází na úrovni vlákna (není blokován celý proces).
- ➕ I programy jádra mohou mít multivláknový charakter.
- ➖ Přepojování mezi vlákny stejného procesu zprostředkovává jádro (tj. pomaleji).
- ➖ Při přepnutí vlákna se 2x přepíná režim procesoru (tj. režie navíc).
- Plánování na bázi vláken již v jádře OS.
- Příklady
- OS/2
- Windows 95/98/NT/2000/XP/7/8
- Solaris
- Tru64 UNIX
- BeOS
- Linux
Plánování procesů a vláken
Přepnutí kontextu
Vyžádá se služba, akceptuje se některé asynchronní přerušení, obslouží se a nově se vybere jako běžící proces.
Když OS přepojuje CPU z procesu X na proces Y, musí:
- Uchovat (uložit v PCB procesu X) stav původně běžícího procesu.
- Zavést stav nově běžícího procesu (z PCB procesu Y).
Přepnutí kontextu představuje režijní ztrátu (zátěž)
- Během přepínání systém nedělá nic efektivního.
- Doba přepnutí závisí na konkrétní HW platformě (počet registrů procesoru, speciální instrukce pro uložení/načtení všech registrů procesoru apod).
Při přerušení musí procesor:
- Uchovat čítač instrukcí.
- Zavést do čítače instrukcí hodnotou adresy vstupního bodu ovladače přerušení z vektoru přerušení.
Fronty plánování procesů
- Fronta úloh
- seznam všech procesů v systému
- Fronta připravených procesů
- seznam procesů uložených v hlavní paměti a připravených k běhu
- Fronta na zařízení
- seznam procesů čekajících na I/O operaci
- Fronta odložených procesů
- seznam procesů čekajících na přidělení místa v hlavní paměti
- Fronta na semafor
- seznam procesů čekajících na synchronizační událost
Strategický (dlouhodobý) plánovač
- Obecně nemusím mít všechny úlohy, které chci spustit, v operační paměti.
- Fronta všech úloh může být značně dlouhá a plánovač musí rozhodnout, které úlohy zavést do paměti a spustit.
- Toto je úkol dlouhodobého (strategického) plánovače
- Vybírá který proces lze zařadit mezi připravené procesy.
- Plánovač je spouštěn je relativně málo často.
- Typicky při ukončení jednoho procesu rozhodne, kterou úlohu dále vybrat k zavedení do paměti a spuštění.
- Nemusí být super rychlý.
- Určuje stupeň multiprogramování.
Krátkodobý plánovač
- Přiděluje procesor připraveným procesům.
- Je spouštěn často (např. každých 10ms) ⇒ musí být rychlý.

Střednědobý (taktický) plánovač
- Vybírá který proces lze zařadit mezi odložené procesy.
- Vybírá který odložený proces lze zařadit mezi připravené procesy.
- Náleží částečně i do správy operační paměti.
- Kapacita FAP je omezená a odložené procesy uvolňují paměť.

Algoritmy
FCFS
Algoritmus „Kdo dřív přijde, ten dřív mele“ (First Come, First Served).
Př.:
- P1 (vyžaduje 24 dávek CPU)
- P2 (vyžaduje 3 dávky CPU)
- P3 (vyžaduje 3 dávky CPU)
- P1, P2, P3
- Doby čekání: P1 = 0, P2 = 24, P3 = 27
- Průměrná doba čekání: (0+24+27)/3 = 17

- P2, P3, P1
- Doby čekání: P2 = 0, P3 = 3, P1 = 6
- Průměrná doba čekání: (6+0+3)/3 = 3

Synchronizace procesů
Se souběžně běžícími procesy se můžeme setkat buď v přímo paralelním prostředí, kde je jedna paměť sdílena více procesy, nebo v prostředí distribuovaném, kde má každý proces vlastní lokální paměť. Hlavním problémem výskytu souběžných procesů je sdílení prostředků (paměť, zařízení, soubory, atd.) Tento problém se vyskytuje dokonce i v mnohouživatelských OS, kdy se např. řeší sdílení paměti mezi hlavní linií výpočtu v jádře a obslužnou rutinou přerušení při I/O operaci. Především při sdíleném přístupu do paměti nebo do souboru mohou vznikat neočekávané problémy – časové závislé chyby.
Vzájemné vyloučení
Vzájemné vyloučení je prostředek, jak zamezit dvěma procesům, aby zároveň přistupovaly k určitým datům nebo prováděly současně určité operace. Jedná se obvykle o funkce, po nichž požadujeme, aby je jeden proces provedl celé sám bez přerušování jinými procesy. Obecně se těmto funkcím říká kritické sekce. Kritické sekci obvykle předchází tzv. preludium (vstup do KS) – místo soupeření procesů o vstup – a je ukončena tzv. postludiem (výstup z KS) – kritická sekce je opět uvolněna pro jiný proces.
Kritická sekce
Problémem kritické sekce je umožnit přístup ke kritické oblasti procesům, které o to usilují, při dodržení následujících podmínek:
- výhradní přístup - v každém okamžiku smí být v kritické sekci nejvýše jeden proces
- vývoj - rozhodování o tom, který proces vstoupí do kritické sekce, ovlivňují pouze procesy, které o vstup do kritické sekce usilují; toto rozhodnutí pro žádný proces nemůže být odkládáno do nekonečna; nedodržení této podmínky může vést například k tomu, že je umožněna pouze striktní alternace (dva procesy se při průchodu kritickou sekcí musí pravidelně střídat)
- omezené čekání; pokud jeden proces usiluje o vstup do kritické sekce, nemohou ostatní procesy tomuto vstupu zabránit tím, že se v kritické sekci neustále střídají - mohou do této kritické sekce vstoupit pouze omezený počet krát (zpravidla pouze jednou)
Pokud o přístup do kritické sekce usiluje některý proces v době, kdy je v ní jiný proces, případně o přístup usiluje v jednom okamžiku více procesů, je nutné některé z nich pozdržet. Toto pozdržení je možné realizovat smyčkou. Toto tzv. aktivní čekání (busy waiting) však zbytečně spotřebovává čas CPU - je možné čekající proces zablokovat a obnovit jeho běh až v okamžiku, kdy proces, který je v kritické sekci, tuto sekci opustí.
Nástroje a algoritmy pro vzájemné vyloučení
- aktivní čekání – softwarově – pouze vzájemná výlučnost R/W s pamětí, bez podpory programovacího jazyka / OS
- aktivní čekání – speciální instrukce TST, EXCHANGE – bez podpory programovacího jazyka / OS
- pasivní čekání – podpora v programovacím jazyku / OS: semafory, monitory, zasílání zpráv
Sdílené vzájemné vyloučení
Jedná se o exkluzivní vzájemné vyloučení operací zápisu s jakoukoli jinou operací a sdílené čtení. U tohoto typu vzájemného vyloučení se objevuje také další typ úloh – tzv. úloha o čtenářích a písařích.
Úloha o čtenářích a písařích
- libovolný počet čtenářů může číst ze sdílené oblasti, v jednom okamžiku smí do sdílené oblasti zapisovat pouze jeden písař, jestliže písař píše do sdílené oblasti, nesmí současně z ní číst žádný čtenář.
- Příklad výskytu této úlohy v praxi může vypadat takto: sdílenou oblast reprezentuje knihovna programů, čtenáři nazveme sestavující programy a písařem může být knihovník.
- Řešení úlohy o čtenářích a písařích:
- priorita čtenářů (pomocí semaforů) – první čtenář zablokuje všechny písaře, poslední čtenář je uvolní, písaři mohou stárnout
- priorita písařů (pomocí semaforů) – první čtenář zablokuje všechny písaře, poslední čtenář je uvolní, první písař zakáže přístup novým čtenářům
- priorita písařů (zasíláním zpráv) – první čtenář zablokuje všechny písaře, poslední čtenář je uvolní, první písař zakáže přístup novým čtenářům, ke sdílené oblasti řídí přístup referenční monitor se třemi mailboxy, každý čtenář / písař má svůj mailbox
Uváznutí
Množina procesů P uvázla, jestliže každý proces Pi z P čeká na událost (uvolnění prostředků, zaslání zprávy), kterou vyvolá pouze některý z procesů P.
Nutná a postačující podmínka uváznutí
- Nutné podmínky uváznutí:
- vzájemné vyloučení (Mutual exclusion)
- se sdíleným zdrojem může v jednom okamžiku pracovat právě jeden proces
- inkrementálnost požadavků (též postupné uplatňování požadavků, Hold-and-Wait)
- proces vlastnící nějaký zdroj potřebuje ke své činnosti zdroj další, který je však držen jiným procesem
- nepředbíhatelnost (No preemption)
- zdroje lze uvolnit pouze procesem, který tyto vlastní a to pouze dobrovolně, až je nebude potřebovat
- Postačující podmínka:
- cyklické čekání (též zacyklení pořadí, Circular Wait)
- důsledek prvních tří nutných podmínek
- existuje množina n procesů (P0…Pn), kde proces P0 čeká na uvolnění zdroje drženého procesem P1, P1 čeká na uvolnění zdroje drženého P2 atd. až Pn čeká na uvolnění zdroje drženého P0
Bezpečný stav
Stav je bezpečný, jestliže systém může alokovat zdroje každému procesu (v mezích maximálního počtu) v nějakém pořadí a zároveň nenastane deadlock (uváznutí). Formálně, systém je v bezpečném stavu, jestliže existuje bezpečná sekvence. Sekvence procesů <P1, P2, …, Pn> je bezpečná pro aktuální stav alokace, jestliže každému procesu Pi mohou být přiděleny požadované zdroje ze zdrojů volných + zdrojů držených procesy Pj, kde j < i. Za této situace, pokud zdroje požadované procesem Pi nejsou momentálně volné, potom Pi čeká, dokud nejsou ukončeny všechny procesy Pj. V momentě, kdy dokončeny jsou, Pi může dostat všechny požadované zdroje, splnit svou úlohu, zdroje uvolnit a skončit. Je-li proces Pi ukončen, může dostat všechny požadované zdroje proces Pi+1 atd. Pokud v systému neexistuje bezpečná sekvence, říkáme o něm, že není bezpečný.
Metody ochrany proti uváznutí
- ignorovat je - přestože tato strategie vypadá nepřijatelně, používá ji například OS Unix; v případě uváznutí musí zasáhnout některý z uživatelů a jeden nebo více procesů násilím ukončit; v krajním případě může být nutné znovu nastartovat celý systém
- prevence uváznutí – ruší se platnost některé nutné podmínky
- detekce uváznutí – detekuje se existence uváznutí a řeší se následky
- vyhýbání se uváznutí – zamezuje se současné platnosti nutných podmínek
- nepřímé metody (zneplatnění nutné podmínky)
- virtualizace prostředků – rušení vzájemné výlučnosti (mimo spooling nepoužitelné)
- požadování všech prostředků najednou – ruší se požadavek inkrementálnosti požadavků
- klady: nemusí se nic odebírat, vhodné pro procesy s jednou nárazovou činností
- zápory: neefektivní, možná prodleva při zahájení procesu
- odebírání prostředků – ruší se vlastnost nepředbíhatelnosti procesů z hlediska používání prostředků
- 1. možnost: proces, jemuž byl odmítnut požadavek, uvolní vše co vlastní a o vše požádá znovu
- 2. možnost: jestliže proces požaduje prostředek držený jiným procesem, držitel je požádán, aby uvolnil vše co vlastní a o vše požádal znovu (procesy nesmí být stejné priority)
- klady: vhodné pro prostředky s uchovatelným a obnovitelným stavem (FAP, procesor)
- zápory: režijní ztráty, možnost cyklického restartu
- přímé metody (nepřipuštění planosti postačující podmínky)
- uspořádání prostředků – ruší se možnost vzniku zacyklení při čekání: procesy smí požadovat prostředky pouze ve stanoveném pořadí
- klady: lze kontrolovat při kompilaci, nic se neřeší za běhu
- zápory: neefektivní
Detekce uváznutí
„každý dostává co chce kdy chce“, OS periodicky testuje existenci uváznutí (detekce cyklu v grafu), klady: žádný prostoj při zahájení, zápory: nutnost řešit uváznutí a posteriori
Způsoby řešení uváznutí
- zrušit všechny uváznuté procesy (nejčastěji používaná metoda)
- návrat uváznutých procesů k poslednímu kontrolnímu bodu (možnost opakování situace)
- postupně rušit uváznuté procesy (podle spotřebovaného času procesoru, počtu tiskových řádků, času do dokončení procesu, priority, množství vlastněných prostředků)
- postupně předbíhat uváznuté procesy
- zamezit současné platnosti nutných podmínek
- bankéřův algoritmus
Algoritmus prevence uváznutí
Základní myšlenkou je zajistit, aby systém byl neustale v bezpečném stavu. Na počátku systém v bezpečném stavu pochopitelně je. V okamžiku, kdy proces žádá zdroj, který je aktuálně volný, musí systém rozhodnout, zda procesu zdroj přidělí, nebo ho nechá čekat. Zdroj může byt procesu přidělen pouze v případě, ze systém i po přiděleni zůstane v bezpečném stavu.
Bankéřův algoritmus
- Algoritmus grafu alokace zdrojů je použitelný pouze v systému, kde každá třída zdroje obsahuje max. 1 instanci. Algoritmus, který si popíšeme nyní, tento problém eliminuje. Není ovšem tak efektivní jako algoritmus grafu alokace zdrojů.
- Když vstoupí novy proces do systému, musí deklarovat maximální počet instanci všech tříd, které bude pro svůj běh potřebovat. Tato maxima nesmi přesahovat celkový počet zdrojů v systému. Když uživatel požaduje množinu zdrojů, musí systém zjistit nepřevede-li alokace těchto zdrojů systém do nebezpečného stavu. Pokud by tomu tak bylo, musí proces čekat než jiný proces neuvolní dostatek zdrojů. V případe opačném jsou zdroje procesu alokovány.
- Pro zajištěni chodu bankéřova algoritmu je třeba udržovat množství datových struktur. Tyto struktury kódují stav systému alokace zdrojů. Nechť n je celkový počet procesu v systému a m je počet typu zdrojů. Potřebujeme následující datové struktury:
- Volny: vektor delky m indikujici pocet volnych instanci kazdeho typu zdroje. Jestlize Volny(j) = k, potom je v systemu k volnych instanci zdroje Rj.
- Max: matice typu (n,m) definujici maximalni pozadavek kazdeho procesu na kazdou tridu zdroju. Jestlize Max(i,j) = k, potom proces Pi muze pozadat maximalne o k instanci zdroje Rj.
- Alokace: matice typu (n,m) definujici pocet zdroju kazde tridy aktualne alokovany kazdemu procesu. Jestlize Alokace(i,j) = k, potom proces Pi ma momentalne alokovano k instanci zdroje tridy Rj.
- Potreba: matice typu (n,m) definujici zbyly pocet instanci zdroje kazde tridy nutny k dokonceni ulohy. Jestlize Potreba(i,j) = k, potom proces Pi potrebuje k dokonceni sve ulohy dalsich k instanci tridy Rj.
- Uvedene datove struktury se v case meni jak co do velikosti, tak co do hodnoty. Pro zjednoduseni prezentace Bankerova algoritmu definujme nasledujici vztah: Necht X a Y jsou vektory delky n. Potom X < = Y tehdy a jen tehdy, jestlize X(i) < = Y(i) pro vsechna i = 1, .. ,n. Napriklad jestlize X = (1, 7, 3, 2) a Y = (0, 3, 2, 1), potom Y < = X. Dale X < Y tehdy, jestlize X < = Y a zaroven X < > Y.
- Kazdou radku matic Alokace a Potreba muzeme zpracovavat jako vektor a oznacovat jako Alokacei a Potrebai. Vektor Alokacei specifikuje zdroje, ktere jsou aktualne alokovany procesu Pi a vektor Potrebai specifikuje dalsi zdroje, ktere proces Pi potrebuje pro sve dokonceni.
Příklad
- Zdroj typu A ma 10 instanci
- zdroj typu B ma 5 instanci
- zdroj typu C 7 instanci
Necht v case t0 je system v nasledujicim stavu:
| Alokace | Max | Volny | |||||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | C | A | B | C | A | B | C | |
| P0 | 0 | 1 | 0 | 7 | 5 | 3 | 3 | 3 | 2 |
| P1 | 2 | 0 | 0 | 3 | 2 | 2 | |||
| P2 | 3 | 0 | 2 | 9 | 0 | 2 | |||
| P3 | 2 | 1 | 1 | 2 | 2 | 2 | |||
| P4 | 0 | 0 | 2 | 4 | 3 | 3 | |||
- Obsah matice Potreba je definovan rozdilem Max - Alokace a je tedy:
| Potreba | |||
|---|---|---|---|
| A | B | C | |
| P0 | 7 | 4 | 3 |
| P1 | 1 | 2 | 2 |
| P2 | 6 | 0 | 0 |
| P3 | 0 | 1 | 1 |
| P4 | 4 | 3 | 1 |
- V teto situaci je system v bezpecnem stavu. Sekvence < P1, P3, P4, P2, P0,> je bezpecna sekvence.
Práce s pamětí, logický a fyzický adresový prostor, správa paměti a způsoby jejího provádění
Obecné poznatky správy paměti
Pro běh procesu je nutné, aby program, který ho řídí, byl umístěn v operační paměti.
- Program se převádí do formy schopné interpretace procesorem ve více krocích, jednou musí někdo rozhodnout kde bude v operační paměti (FAP) umístěn.
- Roli dlouhodobé paměti programu plní vnější paměť.
- Vnitřní operační paměť uschovává data a programy právě běžících, resp. plánovatelných procesů.
- Správa paměti je předmětem činnosti OS, nelze ji nechat na aplikačním programování. Výkon jejich funkcí by byl neefektivní až škodlivý.
- Správa paměti musí zajistit, aby sdílení FAP mezi procesory bylo transparentní a efektivní a přitom bezpečné.
Požadavky na správu paměti
Možnost relokace programů
- programátor nemůže vědět, ze které části paměti bude jeho program interpretován
- při výměnách mezi FAP a vnější paměti (odebírání a vracení paměťového prostředku procesu) může být procesu dynamicky přidělena jiná (souvislá) oblast paměti než kterou opustil - swapping
- swapping umožňuje OS udržovat velký bank připravených procesů.
- odkazy na paměť v programu (LAP) se musí dynamicky překládat na skutečné adresy ve FAP
Nutnost ochrany
- procesy nesmí být schopné se bez povolení odkazovat na paměťová místa přidělená jiným procesům nebo OS
- relokace neumožňuje, aby se adresy kontrolovaly během kompilace
- odkazy na paměť se musí kontrolovat při běhu procesu hardwarem
Logická organizace
- Uživatelé tvoří programy jako moduly se vzájemně odlišnými vlastnostmi
- execute-only – moduly s instrukcemi
- read-only nebo read-write – datové moduly
- private nebo public – moduly s omezením přístupu
Možnost sdílení
- více procesů může sdílet společnou část paměti aniž by došlo k porušení její ochrany
- sdílený přístup je lepší než udržování konzistence kopií, které vlastní jednotlivé procesy
LAP a FAP
Správa paměti, základní pojmy
Logický adresový prostor (LAP): virtuální adresový prostor, se kterým pracuje procesor při provádění kódu (každý proces i jádro mají svůj). Dán šířkou a formou adresy. Kapacita je dána šířkou adresy v instrukci.
Fyzický adresový prostor (FAP): adresový prostor fyzických adres paměti (společný pro všechny procesy i jádro). Adresa akceptovaná operační pamětí. Kapacita je dána šířkou adresové sběrnice operační paměti
Vázání adres LAP na adresy FAP
- při kompilaci
- Je-li umístění ve FAP známé před překladem, kompilátor generuje absolutní program (obraz programu ve FAP)
- při změně umístění ve FAP se musí překlad opakovat
- při zavádění
- umístění ve FAP je známé při sestavování nebo při zavádění programu
- překladač generuje object module, jehož cílovým adresovým prostorem je LAP
- vazby na adresy FAP provádí zavaděč
- při běhu
- cílovým prostorem sestavení je LAP
- program se zavede do FAP ve tvaru pro LAP
- vázání se odkládá na dobu běhu – při interpretaci instrukce
- nutná HW podpora
- proces může měnit svoji polohu ve FAP během provádění
Přidělování souvislých oblastí
Operační paměť (FAP) je typicky rozdělena na dvě části:
- sekce pro rezidentní část OS, obvykle bývá umístěna od počátku
- sekce pro uživatelské procesy
Pro ochranu procesů uživatelů mezi sebou a OS při přidělování sekce procesům lze použít schéma s relokačním a mezním registrem:
- relokační – hodnota nejmenší adresy sekce ve FAP
- mezní – rozpětí logických adres 0..*, přičemž logická adresa použitá v procesu musí být menší než mezní registr
Problém při přidělování více souvislých sekcí. Dynamicky vznikají a zanikají úseky dostupné paměti, které jsou roztroušené po FAP. Procesu se přiděluje takový úsek ve FAP, který uspokojí jeho požadavky. Evidenci úseků (volných i obsazených) udržuje právě OS.
Způsoby rozhodování přidělování:
- First-fit – první dostatečně velký úsek paměti
- Best-fit – nejmenší dostatečně dlouhý úsek paměti
- Worst-fit – největší volný úsek paměti
Rychlostně i kvalitativně jsou First-fit a Best-fit lepší, než Worst-fit. Nejčastěji používaný je First-fit.
Fragmentace
- Vnější – souhrn volné paměti je dostatečný, nikoliv však v dostatečně velkém souvislém bloku
- Vnitřní – přidělená oblast paměti je větší, než požadovaná velikost, přebytek je nevyužitelná část paměti
Fragmentace je snižována setřásáním – přesun sekcí s cílem vytvořit velký úsek paměti. Použitelné jen pokud je možná dynamická relokace (řeší MMU – Memory Management Unit). Provádí se v době běhu.
Výměny (Swapping)
Sekce FAP přidělená procesu je vyměňována mezi vnitřní a vnější pamětí oběma směry (roll out, roll in). Velmi časově náročné (srovnej přístupové doby do RAM a na HDD). Princip používaný mnoha OS ve verzích nepodporujících virtualizaci paměti – UNIX, Linux, Windows
Překryvy (Overlays)
Historická, klasická technika. V operační paměti se uchovávají pouze ty instrukce a data, která je potřeba zde uchovat „v nejbližší budoucnosti“. Vyvolávání překryvů je implementované uživatelem, není potřeba speciální podpory ze strany OS.
Stránkování
- LAP procesu není zobrazován do jediné souvislé sekce FAP, zobrazuje se po částech do volných sekcí FAP
- FAP se dělí na rámce – pevná délka (např. 512 B)
- LAP se dělí na stránky – pevná délka shodná s délkou rámců
- OS si udržuje seznam volných rámců
- Pořadí přidělených rámců ve FAP nesouvisí s pořadím stránek v LAP
- Překlad LAP → FAP je realizován tabulkou stránek (Page Table), jejíž obsah nastavuje OS
- PT je uložena v operační paměti.
- Zpřístupnění údaje v vyžaduje dva přístupy do paměti (do PT a pro operand)
- Problém snížení efektivnosti dvojím přístupem lze řešit speciální rychlou HW cache (asociativní paměť, TLB – Translation Look-aside Buffer)
Zdroje
- slidy PB153
- 04 Principy výstavby OS
- 05 Procesy
- 06 Vlákna
