Obsah
AP12 Pravděpodobnost a statistika
(klasická a podmíněná pravděpodobnost, distribuční funkce a rozdělení náhodných veličin, výpočet střední hodnoty, rozptylu a kovariance)
Pravděpodobnost náhodného jevu je číslo, které je mírou očekávatelnosti výskytu jevu. 1)
(Popisná) statistika je zpracování číselných dat o nějakém souboru objektů.
Matematická statistika je věda aplikovaná na problémy spojené se sběrem a pozorováním náhodných dat.
Terminologie
= množina všech možných výsledků, základní prostor. Prvky
představují jednotlivé možné výsledky.
Jevové pole je systém podmnožin základního prostoru uzavřený na konečné průniky, spočetná sjednocení a množinové rozdíly. Jednotlivé množiny
nazýváme náhodné jevy (vzhledem k
).
Základní pojmy
- jistý jev je celý základní prostor
- nemožný jev je prázdná podmnožina
- elementární jevy jsou jednoprvkové podmnožiny
- společné nastoupení jevů
je jejich průnik, tedy odpovídá jevu
,
- nastoupení alespoň jednoho z jevů
- neslučitelné jevy
jsou jevy, pro které platí
=
- jev A má za důsledek jev B, když
- opačný jev k jevu A je jev
, píšeme
Pravděpodobnostní funkce je funkce na jevovém poli
Vlastnosti pravděpodobnostní funkce
- je nezáporná, tj.
pro všechny jevy
,
- je aditivní, tj.
, pro každý nejvýše spočetný systém po dvou neslučitelných jevů (laicky: „dá se sčítat, když jsou jevy neslučitelné“),
- pravděpodobnost jistého jevu je 1.
- pravděpodobnost opačného jevu je
Pravděpodobnosti
Rozlišujeme dvě definice pravděpodobností: klasickou a geometrickou. Pokud klademe podmínky, bavíme se o tzv. podmíněné pravděpodobnosti.
Klasická pravděpodobnost
Klasická pravděpodobnost je pravděpodobnostní prostor s pravděpodobnostní funkcí
.
Jednoduchý príklad
Zadanie: Hádžeme kockou. Aká je pravdepodobnosť, že hodíme číslo 6?
Riešenie:
- úspešný výsledok (hodená 6)
- všetky možné výsledky (1 až 6)
.
Geometrická pravděpodobnost
Zde je definice pravděpodobnosti založena na porovnání objemů, ploch či délek geometrických útvarů.
Příklad - jen nastínění řešení
Zadání: Romeo a Julie si smluvili schůzku mezi 12:00 a 13:00. Přijdou náhodně v tomto rozmezí a čekají na sebe 20 minut, nejdéle však do 13:00. Jaká je pravděpodobnost, že se setkají?
Nástin řešení: musíme si vytvořit funkci, která nám v pravděpodobnostním prostoru odděluje jev příznivý od nepříznivého. Potom spočítáme obsah části, která znázorňuje jev příznivý a dělíme obsahem celého prostoru.
Podmíněná pravděpodobnost
Nechť H je jev s nenulovou pravděpodobností v jevovém poli v pravděpodobnostním prostoru
. Podmíněná pravděpodobnost
jevu
vzhledem k hypotéze H je definována vztahem
(napr. „jaká je pravděpodobnost, že při hodu dvěmi kostkami padly dvě pětky, je-li součet hodnot deset?“).
Pravděpodobnost průniku a sjednocení jevů
Definice odpovídá požadavku, že jevy A a H nastanou zároveň, za předpokladu, že A nastal s pravděpodobností 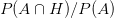 .
.
Je také vidět přímo z definice, hypotéza H a jev A jsou nezávislé tehdy a jen tehdy, je-li .
Přepsáním formule pro podmíněnou pravděpodobnost dostáváme
… závislé
… nezávislé
… závislé
… nezávislé
obecně:
Bayesův vzorec
Pro pravděpodobnost jevů A a B platí
Využíváme jej, když známe podmíněnou pravděpodobnost P(B|A) a chceme zjistit P(A|B).
Jednoduchý příklad
Zadání: Dva střelci vystřelí každý jednu ránu na terč. První má pravděpodobnost zásahu 80%, druhý 60%. V terči se našla jedna rána. Jaká je pravděpodobnost, že patří prvnímu střelci?
Řešení: ,
Jev A: rána patří prvnímu střelci
Pravděpodobnost toho, že se trefí první střelec = (pravděpodobnost, že se první trefí a druhý ne) / (pravděpodobnost, kdy je v terči 1 rána)
Pravděpodobnost, kdy je v terči 1 rána: (bud se prvni trefi a druhy ne a nebo naopak)
2).
Distribuční funkce a rozdělení náhodných veličin
Nahodná veličina –- zavádíme ji, protože chceme pracovat s intervaly – vyjádřit, jaká je pravděpod., že daná hodnota bude právě z tohoto intervalu.
Rozdělení pravděpodobnosti je pravidlo, které přiřazuje pravděpodobnosti událostem nebo tvrzením.
Existuje několik způsobů, jak vyjádřit rozdělení pravděpodobnosti. Nejobvyklejší je uvést hustotu rozdělení pravděpodobnosti; samotná pravděpodobnost jevu se pak získá integrací funkce hustoty.
Diskrétní rozdělení pravděpodobností (definováno na spočetné, diskrétní množině, jako je podmnožina celých čísel) - např. binomické, Poissonovo
Spojité rozdělení (existuje spojitá distribuční funkce, např. polynomická nebo exponenciální) - např. normální rozdělení, exponenciální rozdělení 3)
Distribuční funkce
distribuční funkcí náhodné veličiny X je funkce definovaná pro všechny
vztahem
Diskrétní náhodná veličina X
X na pravděpodobnostním prostoru 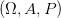 nabývá jen konečně mnoha hodnot
nabývá jen konečně mnoha hodnot 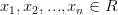 . Pak existuje tzv. pravděpodobnostní funkce f(x) taková, že
. Pak existuje tzv. pravděpodobnostní funkce f(x) taková, že
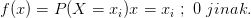 Evidentně
Evidentně 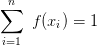 a pro rozdělení pravděpodobnosti platí
a pro rozdělení pravděpodobnosti platí
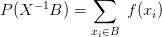 a tedy zejména je distribuční funkce tvaru
a tedy zejména je distribuční funkce tvaru
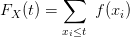 Každá náhodná veličina definovaná pro klasickou pravděpodobnost je diskrétní.
Každá náhodná veličina definovaná pro klasickou pravděpodobnost je diskrétní.
Diskrétní veličinu si můžeme představit jako graf složený z bodů, které odpovídají pravděpodobnosti daného jevu (pro házení kostkou je to 1/6)
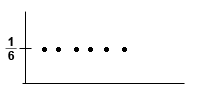 Sečtení hodnot bodů musí dát 1.
Sečtení hodnot bodů musí dát 1.
Distribuční funkce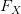 v bodě 3 se vlastně rovná součtu pravděpodobnostních hodnot do tohoto bodu, tedy
v bodě 3 se vlastně rovná součtu pravděpodobnostních hodnot do tohoto bodu, tedy 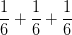
 Sečtení hodnot bodů musí dát 1.
Sečtení hodnot bodů musí dát 1. Distribuční funkce
Spojité náhodné veličině odpovídá spojitá distribuční funkce. , kde f(x) je funkce hustoty pravděpodobnosti.
Funkce hustoty pravděpodobnosti
Nechť X je náhodná veličina, F(x) je její distribuční funkce.
- F je zleva spojitá,
a
.
- Vždy platí
.
- Je-li X diskrétní s hodnotami
, pak je F(x) po částech konstantní,
a
kdykoliv
.
- Je-li X spojitá, pak je F(x) diferencovatelná a její derivace se rovná hustotě pravděpodobnosti X, tj. platí
.
Spojitou veličinu si můžeme představit jako spojitý graf (když například zobrazujeme výšku lidí)
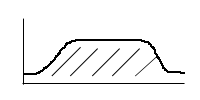 Plocha pod křivkou musí mít obsah 1.
Plocha pod křivkou musí mít obsah 1.
Distribuční funkce se proto vyjadřuje jako integrál.
 Plocha pod křivkou musí mít obsah 1.
Plocha pod křivkou musí mít obsah 1. Distribuční funkce
Rozdělení náhodných veličin
Diskrétní
- sem patří degenerované rozdělení, alternativní rozdělení, binomické rozdělení, Poissonovo rozdělení
Degenerované rozdělení
– konstantní hodnota
- distribuční funkce:
pro
; 1 pro
- pravděpodobn. funkce:
pro
; 0 jinak
Alternativní rozdělení
- A(p) – popisuje pokus s pouze dvěma možnými výsledky (zdar nebo nezdar), pravděpodobnosti jsou p a (1-p):
pro
;
pro
; 1 pro
pro
;
; 0 jinak
Binomické rozdělení
– odpovídá n–krát nezávisle opakovanému pokusu popsanému alternativním rozdělením, přičemž naše náhodná veličina měří počet zdarů.
pro
; 0 jinak
- nejvíce výsledků bude blízko hodnoty np
Příklad s nastíněným řešením
Zadání: Pravděpodobnost narození chlapce je 0,515. Jaká je pravděpodobnost, že mezi deseti tisíci novorozenci bude stejně nebo více děvčat než chlapců?
Řešení: ,
Protože se vlastně nezávisle stále opakuje „pokus“ s výsledkem „kluk“ nebo „děvče“, použijeme Binomické rozdělení Bi(n,p), tedy Bi(10000; 0,515).
…dosadíme 10000 za n
dosadíme do vzorce
Poissonovo rozdělení
– dobře aproximuje binomická rozložení
pro konstantní
a veliká n:
pro
; 0 jinak
Spojité
- sem patří rovnoměrné rozdělení, exponenciální rozdělení, normální rozdělení
Rovnoměrné rozdělení
* R(a, b) -– hustota je konstantní na daném intervalu, jinde je 0
pro
;
pro
; 0 pro
pro
,
Exponenciální rozdělení
pro
; 0 pro
pro
Normální rozdělení
- hustota
Gaussova křivka – rozdělení s touto hustotou se nazývá normální rozdělení N(0,1) (první parametr střední hodnota, druhý rozptyl)
- binomické B(n,p) pro velké n konverguje k normálnímu N(np, np(1 − p))
Výpočet střední hodnoty, rozptylu a kovariance
Výpočet střední hodnoty
- při rovnoměrném rozdělení je střední hodnotou aritmet. průměr
- pro diskrétní veličinu:
- hodnotu vždy vynásobím hodnout její hustoty v daném bodě
- pro spojitou veličinu:
Výpočet rozptylu
- Rozptyl
udává, jak jsou hodnoty „daleko“ od střední hodnoty
- udává se v jednotkách na druhou, zavedla se také výběrová směrodatná odchylka, která se rovná
a udává hodnotu v jednotkách
Aby se dal rozptyl lépe spočítat, můžete využít alternativní vzorec: 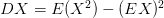 , kde
, kde 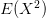 znamená, že do vzorce pro střední hodnotu
znamená, že do vzorce pro střední hodnotu  všude místo
všude místo 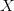 dáme
dáme 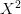 ,
, 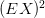 je jen vypočítaná střední hodnota na druhou.
je jen vypočítaná střední hodnota na druhou.
Výpočet kovariance a korelačního koeficientu
Kovariance
- kovariance měří sílu lineární závislosti (jen lineární, jiné závislosti ne)
Korelační koeficient
- Korelační koeficient udává míru lineární závislosti, označuje se
a je to bezrozměrné číslo z intervalu
- Pro
je mezi X,Y přímá lineární závislost. Pro
je mezi X,Y nepřímá lineární závislost. Pro
jsou veličiny X,Y lineárně nezávislé, a říkáme o nich, že jsou nekorelované. Nulová hodnota koeficientu korelace tedy neznamená obecnou nezávislost obou veličin X a Y, ale pouze nezávislost lineární.4)
- pro výpočet potřebuje kovarianci
Příklad
Zadání: Nechť náhodné veličiny U,V mají diskrétní rozdělení určené následující tabulkou:
| U\V | 1 | 2 | 3 |
|---|---|---|---|
| 1 | 0,1 | 0,2 | 0,3 |
| 2 | 0,2 | 0,1 | 0,1 |
Najděte marginální rozdělení obou náhodných veličin, jejich střední hodnoty, rozptyly a korelační koeficient.
Řešení:
Nejprve si jen pro kontrolu můžete spočítat součet všech hodnot v tabulce, pokud je roven 1, je zadání spravné.
Do tabulky si přidáme marginální hodnoty – jsou to laicky řečeno projekce řádků a sloupců
| U\V | 1 | 2 | 3 | P(U) |
|---|---|---|---|---|
| 1 | 0,1 | 0,2 | 0,3 | 0,6 |
| 2 | 0,2 | 0,1 | 0,1 | 0,4 |
| P(V) | 0,3 | 0,3 | 0,4 | 1 |
Spočítáme si střední hodnoty E(V) a E(U) a hodnotu E(UV):
Spočítáme si rozptyl D(V) a D(U):
Spočítáme si kovarianci:
Spočítáme si korelační koeficient: (přibližně)
Důsledek: mezi veličinami U,V je spíše nepřímá lineární závislost. 5)
Zdroj
http://www.fi.muni.cz/~xhalic1/statnice/vypracovaneIM.doc http://www.math.muni.cz/~xpupik/dokumenty/pst-prednasky.pdf http://cs.wikipedia.org/wiki/Kovariance http://cs.wikipedia.org/wiki/Rozdělení_pravděpodobnosti http://cs.wikipedia.org/wiki/Pravděpodobnost
Informace trochu zorganizovala, opravila a doplnila Jitka Pospíšilová.
2)
příklad pochází z cvičení z předmětu MB104
4)
převzato z http://cs.wikipedia.org/wiki/Kovariance
5)
příklad převzat z domácích úkolů předmětu MB104

Diskuze
Pravděpodobnost a statistiku jsem nikdy neměl rád a na její zpracování se fakt necítím :) ale aspoň nějaký základ jsem zkopíroval a malinko upravil od Eleny Halické. K této otázce se ještě nikdo nepřihlásil, tak aspoň torzo tu je pro ty, kteří by ji zpracovat chtěli nebo ty, co netuší, co od této otázky čekat.
No to je fakt skareda otazka… Som z nej uplne uplne mimo (hlavne z tej statistiky.. nikto tomu nerozumie, koho poznam )
)
prevedla jsem ty matematicke znaky do pluginu math – ale statistiku jsem se jeste nezacla ucit, takze jsem tomu zadnou vetsi informacni hodnotu nepridala, jsem si jen jista, ze jsem zadnou neubrala :) … behem dneska ci zitrka se zacnu ucit i statistiku podle mych zapisku z matiky, tak predelam ty zapisy, aby byly spravne (co budu vedet).
vsude jsem misto „velkeho Alfa“ (jevove pole) dala „velke Delta“ – velke Alfa se mi tady totiz nezobrazuje a mit tam jen pismenko A bylo hrozne matouci… jeste mam problem, ze se mi nezobrazuje binomicke cislo, to zatim nevim, jak vyresit.. je jen jedno, tak treba tam dam pak obrazek. Jinak vzorce jsem zatim jen prepsala podle skript pana Slovaka… zatim jim moc nerozumim, zvlast z tech skript, az se to budu ucit ze sesitu matiky, tak treba doplnim neco na pochopeni… a konec neni hotovy, protoze pan Slovak skripta nedokoncil, musim cerpat nekde jinde.
Věci, které jsem dala do modrých rámečků jsou buď příklady, nebo věci sloužící na pochopení. „To důležité“ by mělo být především v normálním textu otázky. Jen u rozdělení náhodných veličin si myslím, že je snad nemožné si ty všechny jednotlive funkce zapamatovat.
Je z toho nakonec výborně zpracovaná otázka. Díky moc!
2 mini chybky su v casti „Rovnomerne rozdeleni“. f(t) je 0 ak je t>=b, F(t) je 1 ak je t>=b. Treba len otocit symboly mensie-vacsie. Myslim si, ze si kazdy sam tu chybku aj tak nasiel…
Dovolil bych si upozornit na zápisky z MB104 ze semestru jaro 2006. Konkrétně na zápisky z 5. (od strany 7), 6. (strana 1), 7. (strana 1–2, 4–9; geometrická pravděpodobnost v zadání této otázky není), 8., 9., 10. a 11. přednášky. Toto téma je tam myslím velmi pěkně vysvětleno.
Je tam pár „překlepů“ (psalo se to v dost svižným tempu), ale snad nic zásadního.
Jestliže jev je prvkem jevového pole a to je systémem podmnožin základního prostoru, pak bych očekával, že i elementární jev, jakožto speciální případ jevu, bude jistou podmnožinou základního prostoru, a ne že bude přímo prvkem tohoto prostoru. Zápis {w} sedí, protože to je množina obsahující právě jeden možný výsledek, ale podle mne má tato množina být prvkem DELTA a nikoliv prvkem OMEGA (prvkem OMEGA je w samotné, nikoliv v množině). Opravte mne, pokud to špatně chápu, nebo opravte (či já opravím) článkem, pokud to chápu správně
myslela jsem si, ze to celkem chapu, ale jak jsi to ted popsal, tak uz si tim vlastne nejsem jista. Kazdopadne cerpala jsem z tohoto dokumentu:
http://is.muni.cz/el/1433/jaro2007/MB104/um/matIV.pdf, konkretne strana 38. Opravuj otazku, jak uznas za vhodne.
Díky za poukázání na zdroj. Myslím, že jsem po chvíli čtení pochopil, jak to prof. Slovák měl tehdy asi na mysli: Když nejprve píše, že celý základní prostor je jistý jev, tak pak elementární jev (taky jev) musí být intuitivně ten celý základní prostor bez něčeho. Tedy pokud víme, že elementární jev je jen nějaká jediná věc, tak pak to musí být celý základní prostor bez všech jeho prvků až na právě jeden. Pokud bychom celý základní prostor označili jako Omega = {omega_1, omega_2, …, omega_n}, pak elementární jev bude {omega_i} pro nějaké i \in {1, 2, …, n}. V materiálu použitý množinový tvar zápisu je tedy dobře, jen už není korektní to „patřítko“, protože prvkem množiny Omega není {omega}, nýbrž omega.
Myslím si, že to vzniklo jako jakási nevhodná zkratka od toho, že elementární jev je jednoprková množina, k tomu, že pro formální správnost nesmí být zapomenuto uvést, že omega je vybírána jako prvek z Omega (což ostatně sice nepřímo, ale velmi přesvědčivě potvrzuje jiná zmínka vztahu těchto proměnných v horní části téže stránky).
Opravil jsem tedy vypracování otázky v tom smyslu, že nikoliv elementární jev je {omega} náležící Omega, ale že elementární jev je {omega} a omega náleží Omega.
K příkladu s Romeem a Julií: Má být funkce, kterou potřebujeme sestavit, skutečně v „prostoru“? To by musela mít tři vstupy, zatímco já si to dovedu představit snadno jako graf se dvěma osami, tedy v rovině.
Aha, možná se tím myslel pravděpodobnostní prostor. Pak by ale bylo vhodné to v článku uvést jasněji.
Ad příklad s distribuční funkcí pro F(3): nemělo by to být jenom 2 * 1/6 namísto 3 * 1/6, protože se to určuje pro X < x a x = 3. Nebo se pletu? Trošku tápu, pokud mi někdo pomůže, tak budu rád.
To stávající řešení odpovídá definici distribuční funkce jak je těsně nad tím rámečem. Ve Wikipedii (cs i en) je ale porovnávání v definici této funkce neostré, takže pokud to náhodou není nějaký zakořeněný zvyk na FI, který by bylo záhodno dodržovat, tak bych se spíš klonil k této asi uznávanější definici, a sice, že ta nerovnost má být neostrá, nikoli ostrá jako je tam teď. Ono nakonec pro nediskrétní náhodné veličiny je ta (ne)ostrost asi docela jedno, ale u těch diskrétních jako v tomto případě už to má docela význam.
Já mám právě v poznámkách ze cvičení ostrou…nicméně tohle je fakt asi detail, kterej nikdo řešit nebude, když víš, co to náhodná veličina je a co je to distribuční funkce
OK, i bych to opravil v textu, ale teď vidím, že by to tam asi způsobilo změny na mnoha místech, tak se do toho radši nechci pouštět. Nicméně tak, jak to tam je teď, je to taky nekonzistentní, jak správně poznamenal. Příklad s kostkou bych ale kvůli tomu neopravoval, protože by mi přišlo dost divné, kdyby se „plýtvalo“ na začátku a P(0) bylo totéž co P(1), zatímco jedničková pravděpodobnost by se získávala nejdříve až jako P(7). Tak to bude muset buď někdo projet a doplnit tam tu možnost rovnosti důkladně, nebo se to zatím nechá tak s tím, že tomu stejně každý už sám rozumí, jak to je
Je to nesmysl něco upravovat, ostrá neostrá..o to nejde. Důležitý je vědět, co v té otázce je
Ahojte, nasel jsem chybku v binomickem rozdeleni, kde by (1-p)^1-t melo spravne byt (1-p)^n-t.
Dalsi chyba je v normalnim rozdeleni, kde hustota fX(x) neni …….e^x, ale …….e^((-x^2)/2).
Je to tak, ze reseni prikladu na geometrickou pravdepodobnost je 5/18?
je to 5/9
V tom priklade na binomicke rozdelenie by IMHO malo byt (n nad t) namiesto (n nad k)
Ten první jednoduchý příklad není zase tak jednoduchý. Ač to do toho autor nezaobalil, již tak se jedná o podmíněnou pravděpodobnost.
Jen tak namatkove chyba je napriklad ve vzorci na Binomicke rozdeleni, ve vzorcich na hustotu a distrib. fci Normalniho rozdeleni. Spravne jsou vzorce treba na wikipedii.
Pokud uvidíš chybu, oprav ji prosím.
binomické rozdělení má být n-t, 1-t - snad po státnicích opravím, teď jsem jaksi na tom bídně s časem:)