Obsah
IN18 Metody analýzy složitosti algoritmů
Zadání
(složitost v nejlepším, nejhorším, průměrném případu, očekávaná složitost)
Vypracování
Úvod
Složitost algoritmu vyjadřuje náročnost algoritmu na různé zdroje v průběhu výpočtu. Tyto zdroje potom určují tzv. míry složitosti, z nichž nejvýznamnější z hlediska informatiky jsou:
- časová (určená časem výpočtu)
- prostorová (určená požadavky na paměť v průběhu výpočtu)
Abychom mohli korektně zavést časovou i prostorovou složitost, je třeba nejprve porozumět pojmům délka výpočtu a množství spotřebované paměti.
Přesné definice těchto pojmů závisí na výpočetním modelu – např. Turingův stroj, RAM, funkcionální jazyk, while-program. Tyto modely jsou z hlediska vyjadřovací síly ekvivalentní (z hlediska výpočetní složitosti samozřejmě ne). Pro zavedení pojmu délka výpočtu budeme uvažovat funkcionální jazyk a imperativní jazyk zastoupený while-programem, abychom zdůraznili efekt referenční transparentnosti funkcionálního jazyka a stavového transformátoru jazyka imperativního.
Časová složitost
Při časové složitosti je důležité rozlišovat mezi dvěma pojmy:
- časová složitost problému
- časová složitost algoritmu (řešícího daný problém)
Platí: časová složitost problému = časová složitost optimálního („nejrychlejšího“) algoritmu pro daný problém
Příklad problému a algoritmů, které problém řeší
Problém: Seřadit neseřazenou posloupnost přirozených čísel
Algoritmy:
Algoritmy:
SelectSort, QuickSort, HeapSort, …
Časovou složitost problému mám zadefinovanou pomocí časové složitosti algoritmu. Tu si zadefinujeme pomocí funkce délky výpočtu algoritmu.
Délka výpočtu
Nechť je výraz. Délkou výpočtu výrazu
rozumíme dobu nutnou pro pro vyhodnocení daného výrazu, a značíme ji
.
je rovna součtu délek vyhodnocení všech výrazů, které
obsahuje. Vyhodnocení elementárních aritmetických, logických, relačních operací nad skalárními operandy je konstantní. Proto i délku výpočtu výrazu, který obsahuje pouze jednoduché operace, považujeme za konstantní.
Délka vyhodnocování závisí také na vyhodnocovací strategii (viz AP7, IN7 Vyhodnocování výrazů).
Vyhodnocování funkce tau
je-li
konstanta
obsahuje-li výraz
zpřístupnění skalární hodnoty uložené v jedné přepisovatelné proměnné
, kde
je některý z primitivních binárních operátorů, které vyhodnocují oba své operandy (
)
pro
pravdivé
pro
pro
- atd.1)
Pro jazyky, které nejsou referenčně transparentní (např. imperativního paradigmatu) musí funkce zohledňovat ještě stav před výpočtem výrazu
a změnu stavu po výpočtu. Funkce
pro jazyky, které nejsou referenčně transparentní, tak bude mít o jeden argument navíc, což bude stav výpočetního systému před výpočtem výrazu
, tedy předpis funkce bude vypadat
.
Časová složitost algoritmu
Víme, že délka výpočtu algortimu záleží od délky vstupu. Podle toho, o jaký případ se zajímáme (při dané délce vstupu), rozlišujeme:2)
- složitost v nejlepším případě
- skoro bezcenná informace
- složitost v nejhorším případě
- asi nejdůležitejší údaj
- určuje složitost algoritmu
- složitost v průměrném případě
- někdy též označována jako očekávaná složitost
- počítá se jako střední hodnota náhodné složitosti při nějakém rozložení vstupních dat
- někdy může být i řádově lepší než složitost v nejhorším případě3)
- pro prakticke použití této složitost je rozhodující fakt, zda-li je málo pravděpodobné, že nastane nejhorší případ
Je-li In množina všech vstupních dat pro algoritmus A, pak pro zavedeme číslo
, které nazveme velikost vstupní hodnoty
. Časovou složitost zavedeme jako funkci
takto:4)
Pro jazyky, které nejsou referenčně transparentní označíme počáteční stav výpočtu, který odpovídá umístění hodnoty
na vstupu a funkci
zavedeme jako:
Časová složitost algoritmu je tedy funkce, která pro každou velikost vstupních dat je rovná délce nejdelšího výpočtu na všech možných datech této velikosti, t.j. rovná se složitosti v nejhorším případě.
Rychlost růstu funkcí
Pro další práci s funkcí délky výpočtu výrazu a pojmem časová složitost algoritmu musíme umět porovnat časové složitosti dvou algoritmů. To uděláme tak, že porovnáme jejich délky výpočtů v závislosti na vstupu v nejhorším případě. Avšak nebudeme porovnávat algoritmy podle absolutní hodnoty délky výpočtu pro dané n; budeme se zajímat pouze a o asymptotické chování funkcí délky výpočtu.
Asymptotické chování funkcí
Neformálně: Jestli se zajímáme o asymptotické chování složitosti algoritmu, pak můžeme zanedbat všechny konstanty a jestli je funkce délky výpočtu ve tvaru součtu funkcí (např. polynom), vybereme pouze funkci která roste nejrychleji (např. vedoucí člen polynomu s koeficientem rovným 1).
Asymptotické porovnání rychlosti růstu funkcí
Definujeme následující množiny funkcí:
Množiny funkcí sloužící k asymptotickému porovnání rychlosti růstu dvou funkcí
- říkáme, že f roste (asymptoticky) nejvýše tak rychle jako g
- říkáme, že f roste (asymptoticky) aspoň tak rychle jako g
- říkáme, že f roste (asymptoticky) pomaleji než g
- říkáme, že f roste (asymptoticky) rychleji než g
- říkáme, že f roste (asymptoticky) stějně rychle jak g
Analýza složitosti
Při analýze složitosti nás většinou zajímají tři druhy složitosti:5)
- horní odhad složitosti problému = složitost konkrétního algoritmu
- dolní odhad složitosti problému
- Dokazuje se o hodně složitěji než horní odhad, protože musíme ukázat, že neexistuje žádný algoritmus, který by problém vyřešil s asymptoticky menší časovo složitostí
- složitost problému
Dolní odhad složitosti problému - techniky
- Informační metoda – řešení problému v sobě obsahuje jisté množství informací a v každém kroku výpočtu jsme schopní určit jen část této informace (násobení matic, cesta v grafu, řazení)
- Redukce
- Metoda sporu
- Varianta A: Za předpokladu, že algoritmus má složitost menší, než uvažovanou hranici, umíme zkonstruovat vstup, na kterém nedá korektní řešení.
- Varianta B: Za předpokladu, že algoritmus najde vždy korektní řešení, umíme zkonstruovat vstup, pro který složitost výpočtu přesáhne uvažovanou hranici.6)
Způsoby výpočtu složitosti algoritmu
Pro určování časové složitosti algoritmu můžeme použít dva přístupy. Nechť A je algoritmus skládající se z kroků :7)
- Klasický přístup – Analyzujeme složitost každé operace. Výsledná složitost je součtem složitostí jednotlivých operací.
- Technika amortizace – Analyzujeme posloupnost jako celek. Tato technika umožňuje, na rozdíl od klasického přístupu mnohem přesnější určení časové složitosti algoritmu. Dává nám průměrnou dobu operace na nejhorších vstupních datech, tedy efektivně horní mez pro průměrnou složitost každé operace algoritmu. Používané metody:
- seskupení
- účtů
- potenciálových funkcí
Poznamenejme, že amortizovaná složitost nepředstavuje další typ složitosti k dříve uvedeným (tj. nejlepší/nejhorší/průměrný případ), ale pouze způsob výpočtu složitosti.
Techniky výpočtu složitosti algoritmu pomocí amortizace
Jednotlivé techniky představíme na příkladě zásobníku.
Zásobník
Operace:
Push(S, x)Pop(S)Multipop(S, k)– vybere k prvků z S, resp. vyprázdní zásobník, je-li |S| < k.
Klasický přístup
Zásobník – příklad na zjištění složitosti klasickou metodou (neamortizovanou složitost)8)
Uvažujeme posloupnost n operacím 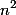 .
.
Pop, Push a Multipop. Push a Pop mají složitosti 1. V posloupnosti n operací má Multipop v nejhorším případě složitost n. Proto celá posloupnost má v nejhorším případě složitost Metoda seskupení
Operace rozdělíme do skupin a analyzujeme složitost celé skupiny operací současně.9)
Zásobník – příklad na zjištění amortizované složitosti metodou seskupení
- Skupina 1 – operace
Push, suma jejich složitostí nepřesáhne n - Skupina 2 – operace
PopaMultipop, suma jejich složitostí (= počet prvků vybraných ze zásobníku) nemůže být větší než počet vykonaných operacíPush(=počet prvků vložených do zásobníku). Složitost cele skupiny proto nepřesáhne n.
Celá posloupnost ma v nejhorším případě složitost .
Metoda účtů
Každé operaci přiřadíme kredit (číslo), které může být různé od její skutečné ceny (složitosti). Při realizaci operace zaplatíme její cenu kredity podle těchto pravidel:10)
- je-li cena operace
kredit operace, tak ze operaci zaplatíme tolik kreditů, jaká je její cena, zbytek kreditů uložíme na účet
- je-li cena operace
kredit operace, tak kredity potřebné pro zaplacení operace vezmeme z účtu.
Počátečný stav účtu je 0 kreditů. Jestli během celého výpočtu zůstane počet kreditů na účtu nezáporný, pak součet kreditů vykonaných operací je cena vykonaných operací.
Platí: Amortizovaná cena operace = počet kreditů přiřazených operaci
- VARIANTA: Kredity přiřadíme objektům datové struktury, nad kterou se operace realizují. Cena operace se zaplatí kredity objektů, se kterými operace manipuluje.
Při důkazu složitosti algoritmu metodou účtů je velmi důležité zvolit si vhodnou kreditaci operací. Téměř vždy to rozhoduje o tom, jestli určíme složitost algoritmu správně.
Zásobník – příklad na zjištění amortizované složitosti metodou účtů
Zvolená kreditová funkce:
| Operace | Cena | Kredity |
|---|---|---|
Push | 1 | 2 |
Pop | 1 | 0 |
Multipop | | 0 |
V okamžiku, když objekt vkládáme do zásobníku, „předplatíme“ si tím jeho výběr
Operaci Push zaplatíme 1 kreditem, 1 kredit dáme na účet. Operace Pop a Multipop zaplatíme kredity z účtu. Lehce dokážeme, že během celého výpočtu platí invariant počet kreditů na účtě je rovný počtu prvků v zásobníku. Z toho plyne, že zůstatek na účtě nikdy neklesne pod 0.
Celková složitost posloupnosti n operací je součet kreditů vykonaných operací
.
Metoda potenciálové funkce
Operace se realizují na datovou strukturou. Potenciálova funkce přiřadí každé hodnotě (obsahu) datové struktury číslo. Uvažujme posloupnost n operací, nechť skutečná cena i-té operace v této posloupnosti je ci. Označme D0 iniciální hodnotu datové struktury a Di její hodnotu po vykonání i-té operace.
Definujeme amortizovanou cenu i-té operace, , předpisem
Součet amortizovaných cen operací je
Za předpokladu, že platí
, t.j. součet amortizovaných cen operací je horním odhadem pro složitost celé posloupnosti operací.
Aby jsme zabezpečili platnost podmínky , definujeme potenciálovou funkci tak, aby pro každou hodnotu D datové struktury platilo, že potenciál
je aspoň tak velký, jak potenciál počáteční hodnoty
datové struktury.11)
Zásobník – příklad na zjištění amortizované složitosti metodou potenciálové funkce
Datová struktura je zásobník.
Potenciálová funkce = počet prvků v zásobníku. Amortizovaná cena i-té operace – rozlišujeme dle typu operace:
Potenciálová funkce = počet prvků v zásobníku. Amortizovaná cena i-té operace – rozlišujeme dle typu operace:
Push | |
Pop | |
Multipop | |
Pro všechny platí
.
Proto složitost celé posloupnosti je
Předměty
Použitá literatura
Vypracoval
Shkodran Gerguri
Adam Libuša, 173122[AT]mail.muni.cz
Otázku si přečetl pan RNDr. Libor Škarvada a rámcově prošel. Jeho podněty pro doplnění textu, opravy nesrovnalostí a odstranění matoucích či k otázce se nevztahujících textů byly do otázky zaneseny. Tato kontrola je jen rámcová, stále se může stát, že v otázce zůstala zapomenutá chybka či nesrovnalost, vyučující za toto nenese odpovědnost, berte tuto rámcovou kontrolu jako formu pomoci od vyučujících pro studenty.
1)
http://www.fi.muni.cz/~libor/vyuka/IB002/stud-materialy/slc-1.ps|Návrh algoritmů I – Doplňující text k přednášce, str. 40-43
2)
https://is.muni.cz/auth/el/1433/jaro2007/IB108/um/slajdy.pdf|Návrh algoritmů II – Slajdy z přednášek, str. 2
3)
http://www.beranr.webzdarma.cz/algoritmy/algoritmy.html|Algoritmy – Radek Beran
4)
http://www.fi.muni.cz/~libor/vyuka/IB002/stud-materialy/slc-1.ps|Návrh algoritmů I – Doplňující text k přednášce, str. 56
5)
https://is.muni.cz/auth/el/1433/jaro2007/IB108/um/slajdy.pdf|Návrh algoritmů II – Slajdy z přednášek, str. 3
6)
https://is.muni.cz/auth/el/1433/jaro2007/IB108/um/slajdy.pdf|Návrh algoritmů II – Slajdy z přednášek, str. 4
7)
https://is.muni.cz/auth/el/1433/jaro2007/IB108/um/slajdy.pdf|Návrh algoritmů II – Slajdy z přednášek, str. 19
8)
https://is.muni.cz/auth/el/1433/jaro2007/IB108/um/slajdy.pdf|Návrh algoritmů II – Slajdy z přednášek, str. 20
9)
https://is.muni.cz/auth/el/1433/jaro2007/IB108/um/slajdy.pdf|Návrh algoritmů II – Slajdy z přednášek, str. 22
10)
https://is.muni.cz/auth/el/1433/jaro2007/IB108/um/slajdy.pdf|Návrh algoritmů II – Slajdy z přednášek, str. 24
11)
https://is.muni.cz/auth/el/1433/jaro2007/IB108/um/slajdy.pdf|Návrh algoritmů II – Slajdy z přednášek, str. 28

Diskuze
co se ucite k teto otazce? co je ocekavana a prumerna slozitost? Prumerna je asi amortizovana, ne? Moc nevim, co si k teto otazce pripravit. Napada me ukazat na nejakym vhodnym prikladu jednotlive slozitosti a tim to asi konci. Mozna jeste zminit slozitostni tridy (podobne jak to je v otazce Slozitost).
Ono je tam toho vic. Napr. metoda uctu, metoda potencialove funkce - to vse se pouziva pri amortizovane slozitosti.
Ja to teda skúsim vypracovať…
Diky.
sorry..obnovil jsem stranku a vlozilo se mi to tam znovu. Jinak dik vsem, kdo pracuji na vypracovani teto otazky.
Tak jsem to prosel, a zda se mi, ze tam nic nechybi.
Ok, díky, teraz ešte keby sa na to pozrel nejaký vyučujúci..
Ok, zkusim napsat Dr. Skarvadovi, prof. Cerne bych radeji nepsal, aby si to nevylozila nejak zle.
Takhle jsem to nemyslel :), spis jde o to, aby ji ta zadost neprisla moc troufala. Kazdopadne jsem uz napsal Dr. Skarvadovi, tak snad se na to podiva.
Otazka je vypracovana pekne, diki :) Mam len jednu pripomienku:
Podla mna zlozitost v priemernom pripade sa nerovna ocakavanej zlozitosti -
1)pride mi to nelogicke preco by do zadania davali 2 terminy, ktore znamenaju to iste
2)myslim si, ze ocakavana zlozitost je nieco ako kolko platnych vystupov ocakavame, tak podla toho sa urci zlozitost - vid Karp-Rabinov alg., kde ocakavana zlozitost je O((n-m+1) + cm), kde c je pocet platnych posunov. Na druhu stranu, zlozitost v priemernom pripade Karp-Rabinovho alg. neviem ako by sa urcovala :)
Diky, snažil som sa :) Nikde som v skriptách nemohol násť definíciu očakávanej zložitosti, tak som čerpal odtiaľto. Tie dve rôzne podotázky - ja viem, tiež ma to napadlo, ale tak som si povedal prečo nie, chceli možno povedať, že to je to isté. Alebo sa možno len rôznia termíny z rôzných zdrojov.
Na druhú stranu ak zoberiem ten pojem z Karp-Rabinovho algoritmu “ nieco ako kolko platnych vystupov ocakavame, tak podla toho sa urci zlozitost“, tak sa mi to zdá dosť podobné tomuto: „počítá se jako střední hodnota náhodné složitosti při nějakém rozložení vstupních dat“ :). Každopádne ak nájdeš niekde nejakú lepšiu definíciu očakávanej zložitosti, kľudne to tam prepíš.